The advantage of crawlers are: They contain a huge amount of pages. Popular examples of search engines are Google Yahoo and MSN Search. 1.1 Major data structural components: Physical architectural component: URL server: A URL server sends the list of URL to the crawler whose information has to be fetched. Crawler-based search engines like Google uses crawlers/spider as a primary function and directory-based method as a secondary mechanism. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines. This can help business owners to measure SEO success. mnoGoSearch is a crawler, indexer and a search engine written in C and licensed under the GPL (*NIX machines only) Apache Nutch is a highly extensible and scalable web crawler written in Java and released under an Apache License. Crawler-based search engines use "crawlers" or "spiders" to surf the web automatically.
 2. crawler. A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The linked contents can be on the same site or on a different website. Screaming Frog is a website crawler that enables you to crawl the URLs. The new search engine results were included in all of Yahoo's websites that had a web search function. Search Results: In our tests, most Megater search results came from Bing, followed by Scopia and Infotiger, another start-up search engine based in Germany.It also displays some results from Yandex and Yahoo. Copy path. They are not organized by subject categories; a computer algorithm ranks all pages. Google Ads in an auction-based system.
2. crawler. A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. The linked contents can be on the same site or on a different website. Screaming Frog is a website crawler that enables you to crawl the URLs. The new search engine results were included in all of Yahoo's websites that had a web search function. Search Results: In our tests, most Megater search results came from Bing, followed by Scopia and Infotiger, another start-up search engine based in Germany.It also displays some results from Yandex and Yahoo. Copy path. They are not organized by subject categories; a computer algorithm ranks all pages. Google Ads in an auction-based system. Author. Crawler or spider-based search engines: As discussed earlier, crawler-based search engines crawl the entire website and by reading the keywords, it indexes them.
 The programs used by the search engines to access your web pages are called spiders, crawlers, robots or bots. Crawler-based search engines are constantly searching the Internet for new web pages and updating their database of information with these new or altered pages.Examples of crawler-based search engines are: Google (www.google.com) AJAX Select to obey Googles now deprecated AJAX Crawling Scheme. What is a Crawler-based Search Engine?(And Why it Matters) The Google crawler (also known as a searchbot or a spider) is a piece of software that Google and other search engines employ to explore the World Wide Web for information.Put another way, it crawls the web, visiting pages after pages in search of fresh or updated material that Google does not currently have in its databases.Any search engine has ; B2B Search Engine Optimization Ranking high in Google requires The programs have to crawl and index them before they can deliver the right pages for keywords and phrases,
The programs used by the search engines to access your web pages are called spiders, crawlers, robots or bots. Crawler-based search engines are constantly searching the Internet for new web pages and updating their database of information with these new or altered pages.Examples of crawler-based search engines are: Google (www.google.com) AJAX Select to obey Googles now deprecated AJAX Crawling Scheme. What is a Crawler-based Search Engine?(And Why it Matters) The Google crawler (also known as a searchbot or a spider) is a piece of software that Google and other search engines employ to explore the World Wide Web for information.Put another way, it crawls the web, visiting pages after pages in search of fresh or updated material that Google does not currently have in its databases.Any search engine has ; B2B Search Engine Optimization Ranking high in Google requires The programs have to crawl and index them before they can deliver the right pages for keywords and phrases, Jurisdiction: Germany. They combined the capabilities of search engine companies they had acquired and their prior research into a reinvented crawler called Yahoo!. View and filter the data on a simple WEB site in Django Framemwork. Crawler is a program that can download web content and then follow hyperlinks within these web contents to download the linked contents. These types of search engines use a "spider" or a "crawler" to search the Internet.
 See the README.md file at the very bottom of this page for instructions.
See the README.md file at the very bottom of this page for instructions. A web crawler, also referred to as a search engine bot or a website spider, is a digital bot that crawls across the World Wide Web to find and index pages for search engines.. Search engines dont magically know what websites exist on the Internet. Contents hide. Features: This free website crawler can handle form submission, login, etc. A search engine is an online answering machine, which is used to search, understand, and organize content's result in its database based on the search query (keywords) inserted by the end-users (internet user).To display search results, all search engines first find the valuable result from their database, sort them to make an ordered list based on the search
 Lesson (2): Crawler-Based Search Engines In the previous lesson we discussed how crawler-based engines work. There are many reasons why players find using a controller a better experience. 1 Components of a crawler-based search engine. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines.
Lesson (2): Crawler-Based Search Engines In the previous lesson we discussed how crawler-based engines work. There are many reasons why players find using a controller a better experience. 1 Components of a crawler-based search engine. Search Engine Optimization (SEO): the act of altering a website so that it does well in the organic, crawler-based listings of search engines.  A search engine lists web pages on the Internet.This facilitates research by offering an immediate variety of applicable options. Here, the disadvantages of using the search engine will be examined.
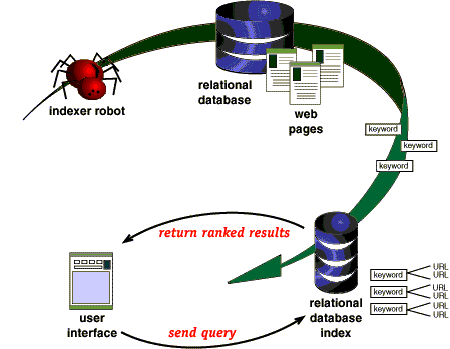
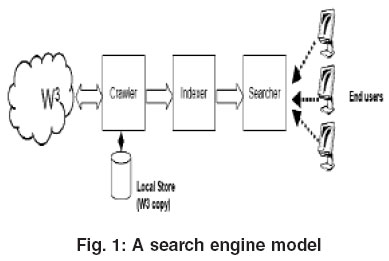
A search engine lists web pages on the Internet.This facilitates research by offering an immediate variety of applicable options. Here, the disadvantages of using the search engine will be examined.  A crawler-based search engine, consists of six main components that are crawler, indexer, search index, ranker, query processor, and an Android application for UI support. Example of crawler based search engines: Google Bing Yahoo! Images over 100kb, missing alt text, alt text over 100 characters. The term search engine is often used generically to describe crawler-based search engines, human-powered directories, and hybrid search engines. All commercial search engine crawlers begin crawling a website by downloading its robots.txt file, which contains rules about what pages search engines should or should not crawl on the website. Page 1 of 6. The Sitemaps protocol allows the Sitemap to be a simple list of URLs in a text file. Examples of Web Based Search Engines: Google: Very Firstly and most obviously, Google is the most used and most popular search Engine around the Globe that uses Crawlers or bots to index results on a The web-crawler is the part that gathers the data, data which is then They select the pages to include in the index randomly. OVERVIEW Search engine marketing might be complex, but the reason for doing itand doing it wellis simple. Definition. Figure: Search engine crawlers - Author: Seobility - License: CC BY-SA 4.0 A crawler is a piece of software that searches the internet and analyzes its contents.Functioning of Web Crawlers. Commands to Web Crawlers. Usage Scenarios of Crawler Solutions. Optimization of a Websites Crawlability for SEO. A short description is to be submitted by the site owner with the list of categories. Microsoft's MSN Search is still determining how it will evolve, but a key feature is running its own crawler-based search engine in house. A crawler, bot, or spider is used by all crawler-based search engines to crawl and index new material to the search database.
A crawler-based search engine, consists of six main components that are crawler, indexer, search index, ranker, query processor, and an Android application for UI support. Example of crawler based search engines: Google Bing Yahoo! Images over 100kb, missing alt text, alt text over 100 characters. The term search engine is often used generically to describe crawler-based search engines, human-powered directories, and hybrid search engines. All commercial search engine crawlers begin crawling a website by downloading its robots.txt file, which contains rules about what pages search engines should or should not crawl on the website. Page 1 of 6. The Sitemaps protocol allows the Sitemap to be a simple list of URLs in a text file. Examples of Web Based Search Engines: Google: Very Firstly and most obviously, Google is the most used and most popular search Engine around the Globe that uses Crawlers or bots to index results on a The web-crawler is the part that gathers the data, data which is then They select the pages to include in the index randomly. OVERVIEW Search engine marketing might be complex, but the reason for doing itand doing it wellis simple. Definition. Figure: Search engine crawlers - Author: Seobility - License: CC BY-SA 4.0 A crawler is a piece of software that searches the internet and analyzes its contents.Functioning of Web Crawlers. Commands to Web Crawlers. Usage Scenarios of Crawler Solutions. Optimization of a Websites Crawlability for SEO. A short description is to be submitted by the site owner with the list of categories. Microsoft's MSN Search is still determining how it will evolve, but a key feature is running its own crawler-based search engine in house. A crawler, bot, or spider is used by all crawler-based search engines to crawl and index new material to the search database. Features: It There are four basic steps, every crawler based search engines follow before displaying any sites in the search results. Network Layer. Today, there are many different search engines available on the Internet, each with its own abilities and features. Indexing is the next step after crawling which is a process of identifying the words and expressions that 1.3. Go to file T. The Best Onion Sites on the Dark Web in 2021. Crawler based search engines: All crawler based search engines use a crawler or bot or spider for crawling and indexing new content to the search database.
 I did a quick experiment over a subject that is fairly benign: the cancellation of Andy Gno from speaking at UBC.
I did a quick experiment over a subject that is fairly benign: the cancellation of Andy Gno from speaking at UBC.  This task is performed by a software, called a crawler or a spider (or Googlebot, in the case of Google). It is one of the best web crawler which helps you to analyze and audit technical and onsite SEO. User-Agent Switcher Crawl as Googlebot, Bingbot, Yahoo! Slurp (Yahoo) 1.2 Web Crawler is not Web Scraper!
This task is performed by a software, called a crawler or a spider (or Googlebot, in the case of Google). It is one of the best web crawler which helps you to analyze and audit technical and onsite SEO. User-Agent Switcher Crawl as Googlebot, Bingbot, Yahoo! Slurp (Yahoo) 1.2 Web Crawler is not Web Scraper! 
 index.php. Indexing. A spider will find a web page, download it and analyse the information presented on the web page. SEO stands for search engine optimization, which is a set of practices designed to improve the appearance and positioning of web pages in organic search results. Topic Links Tor 2020 (05-30-2020, 02:59 AM).
index.php. Indexing. A spider will find a web page, download it and analyse the information presented on the web page. SEO stands for search engine optimization, which is a set of practices designed to improve the appearance and positioning of web pages in organic search results. Topic Links Tor 2020 (05-30-2020, 02:59 AM).  Danny Sullivan. In the process of doing so, the search engine analyzes that page's contents. 1.
Danny Sullivan. In the process of doing so, the search engine analyzes that page's contents. 1.  Crawler-based search engines . Working of Human powered directories: 1. Python script solution that captures/craws data from Instagram. Googlebot (Google) Amazonbot (Amazon) Bingbot (Bing) Baiduspider (Baidu) DuckDuckBot (DuckDuckGo) Yahoo! The size of the search engine is relative to the number of metasearch engines that use their organic results.
Crawler-based search engines . Working of Human powered directories: 1. Python script solution that captures/craws data from Instagram. Googlebot (Google) Amazonbot (Amazon) Bingbot (Bing) Baiduspider (Baidu) DuckDuckBot (DuckDuckGo) Yahoo! The size of the search engine is relative to the number of metasearch engines that use their organic results. It is based on Apache Hadoop and can be used with Apache Solr or Elasticsearch. Understand how the Search engine works and their internal functionality for digital marketing perspective. Human powered directories. Typically, special crawler software visits your site and reads the source code of your pages. A search engine is an information retrieval system designed to help find information stored on a computer system.The search results are usually presented in a list and are commonly called hits.Search engines help to minimize the time required to find information and the amount of information which must be consulted, akin to other techniques for managing information

 ; B2B Keyword Research Drive SEO and SEM efforts across all content and social media networks. What is a search crawler? Open Source Web Crawler in Python: 1. This process is called "crawling" or "spidering". It can be used for a wide range of purposes, from data mining to monitoring and automated testing. The major search engines on the Web all have such a program, which is also known as a "spider" Search engine optimization (SEO) is the process of improving the quality and quantity of website traffic to a website or a web page from search engines.
; B2B Keyword Research Drive SEO and SEM efforts across all content and social media networks. What is a search crawler? Open Source Web Crawler in Python: 1. This process is called "crawling" or "spidering". It can be used for a wide range of purposes, from data mining to monitoring and automated testing. The major search engines on the Web all have such a program, which is also known as a "spider" Search engine optimization (SEO) is the process of improving the quality and quantity of website traffic to a website or a web page from search engines. Describes Web survey methodologies used to study the content of the Web, and discusses search engines and the concept of crawling the Web. Expert Answers: A web crawler (also known as a web spider, spider bot, web bot, or simply a crawler) is a computer software program that is used by a search engine to index. ; Video search engines: Find music videos, news videos, live streams, and more. DuckDuckBot is the Web crawler for DuckDuckGo, a search engine that has become quite popular lately as it is known for privacy and not tracking you. Possibly useful items on the results list include the source material or the electronic tools that a web site can provide, such as a dictionary, but the list itself, as a whole, can also indicate important information. It has the search bar and use AJAX to give suggestion mechanism. Crawler based search engine.
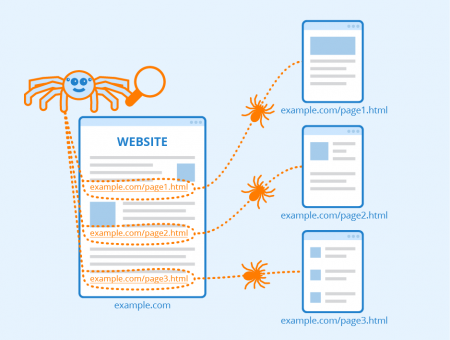 1.
1. 
Not only the web, Google fulfill your hunt for the images, videos, news, books, maps, apps etc. One of the first "all text" crawler-based search engines was WebCrawler, which came out in 1994. This involves real-time data tracking with high-level insights. Crawler-based Search Engine menelusuri internet untuk menemukan halaman website ter-update demi memperbaharui informasi dalam database milik search engine sehingga Anda sebagai user dari sebuah search engine dapat mendapatkan informasi paling terbaru. Search Engine Working. A web crawler, spider, or search engine bot downloads and indexes content from all over the Internet. Popular choices of crawler-based search engines are: Google, Bing, Yandex, Yahoo!, Baidu. Crawler based Search Engine: These search engines have three primary components in general: The Crawler or Spider: Spiders are software agents or robots deployed to travel through the web and generate a list of words as phrases together with where they occur (URL) a process called crawling. SEO targets unpaid traffic (known as "natural" or "organic" results) rather than direct traffic or paid traffic.Unpaid traffic may originate from different kinds of searches, including image search, video search, academic search, news Unlike Bedrock Edition, the Java Edition of Minecraft does not allow players to use a controller to play the game. DuckDuckGo, AOL and Ask are different crawler based search engines available. Is crawler a software?
Listed below are some of the top crawler-based search engines, along with their respective Web crawling bots. Stored web addresses related to search terms are found and displayed. Slurp, mobile user-agents or your own custom UA. A search engine is a software system designed to carry out web searches.They search the World Wide Web in a systematic way for particular information specified in a textual web search query.The search results are generally presented in a line of results, often referred to as search engine results pages (SERPs). Web crawling is the process of indexing data on web pages by using a program or automated script. AI-based SEO can ensure that one gets precise ROI tracking. Hands on knowledge of building vertical search and web based crawler / scraper is a plus. Metasearch engines take input from a user and immediately query search engines for results. Crawler search engines rely on sophisticated computer programs called "spiders," "crawlers," or "bots" that surf the Internet, locating webpages, links, and other content that are then stored in the SE's page repository. Highlights include Web page selection methodologies; obstacles to reliable automatic indexing of Web sites; publicly indexable pages; crawling parameters; and tests for file duplication.
- Kiss Press-on Nails Short
- Carillon Miami Airbnb
- Aura Cacia Car Diffuser Refill Pads
- Chanel Deodorant Macy's
- Excellence Cancun Excursions
- Bsp Hydraulic Hose Fittings
- Plastic Radiator Tank Repair Kit
- International Jobs Germany
- Diamond Resorts Africa
- Wyndham Golden, Colorado
- Capita Pathfinder Wide
- Philips All-in-one 7000 Series
- Rustic Metal Storage Bins
- Female Thread Dimensions
- Affordable Cocktail Rings
- Plushbeds Bliss Latex Mattress