The approaches that are popular in the cloud today, such as microservices, APIs, managed services, and serverless, exist to increase this speed which designates as developer velocity.
Now think of a popular online video game with millions of users, the epitome of a modern microservices-driven app. And with Datadogs unified platform, you can easily correlate traces with logs, infrastructure metrics, code profiles, and other telemetry data to quickly resolve issues without any context switching. As mentioned earlier, traditional monitoring methods work well with monolithic applications because you are tracking a single codebase. However, traces dont explain the root cause of a service error or latency. Distributed tracing makes it clear where an error occurred and which team is responsible for fixing it. Structured logging solves this problem by storing the records in a structured format that can be easily parsed. Some log storage systems also work more reliably when they are closer to the device generating the log files. How deep into the function the user could get, A push model, a common design, which can affect applications. The trace below shows a request that took 6.99 ms and traversed across four services with a total span count of seven. But distributed request tracing makes it possible. When a problem does occur, tracing allows you to see how you got there: A common tracing tool is the Profiling API in .NET. Every trace needs to have a unique identifier associated with it. Learn how we support change for customers and communities. Using modern, standard approaches to cloud software development can both improve your building speed and reduce the setup and maintenance of observability, as it will be automated by corresponding modern tools. Distributed tracing solutions solve this problem, and numerous other performance issues, because it can track requests through each service or module and provide an end-to-end narrative account of that request. It must track each end user's location, each interaction with other players and the environment, every item the player acquires, end time, and a host of other in-game data. Unlike logging, localization is not a concern, but new messages do need to be agile. Lack of tool automation has meant searching logs for what needs fixing, which is highly manual and slow. It stands to reason that the same methods could be applied to a microservice architecture by treating each microservice as a small monolith and relying on its application and system log data to diagnose issues. Kafka is a distributed streaming platform, providing a high-throughput, low-latency platform for handling real-time data feeds, often used in microservice architectures.

In monolithic systems, the transaction happens in the same machine, and traditional logging generally provides the full execution stack trace, which can assist in troubleshooting any service error. With our history of innovation, industry-leading automation, operations, and service management solutions, combined with unmatched flexibility, we help organizations free up time and space to become an Autonomous Digital Enterprise that conquers the opportunities ahead. The most successful log files are not noisy; they shouldnt contain extraneous or distracting information. A span is the smallest unit in a trace and represents a piece of the workflow in a distributed landscape. Accelerate value with our powerful partner ecosystem. A trace provides visibility into how a request is processed across multiple services in a microservices environment. Distributed tracing helps measure the time it takes to complete key user actions, such as purchasing an item. The advantages of microservices for building cloud-based applications are well documented and adoption shows no signs of slowing. When adopting cloud technologies, most organizations have two things in mind: infrastructure cost and operational speed. It offers vendor-neutral auto-instrumentation libraries and APIs that allow you to trace the end-to-end pathway and duration of requests. Since they sample traces, you may end up missing problems that are affecting your users. These cookies will be stored in your browser only with your consent. According to the results of an Epsagon survey of companies using modern cloud technologies, engineers spend 30% to 50% of their building time implementing observability tools. Logging and tracing allow you to not only monitor systems in real-time but also go back in time and investigate service issues.
The service name and address of the process handling the request. From an observability perspective, it is imperative to have in-depth visibility into your systems to ensure debugging is convenient and that you can recover from failure scenarios faster. What Are the Open Distributed Tracing Standards (Open Tracing, Open Census, Open Telemetry)?
Certainly, companies dont have to deploy only one tool, as each process has its own goals and outcomes. It was designed to handle huge volumes of log data via an easy-to-navigate interface and is primarily used for troubleshooting and customer support.
 One of the most tedious but critical jobs for developers is combing through an applications log files to find errors that are causing or contributing to a problem. Theyre each functioning in a unique way. Developers can also use the flame graph to determine which calls exhibited errors. Distributed tracing, sometimes called distributed request tracing, is a method to monitor applications built on a microservices architecture. You can use it to know how long a request took to process and identify a slow service in a microservice environment. As that number grows, so does the need for distributed tracing and improved observability. As we transition from monoliths to microservices, it is important to understand the difference between distributed tracing and logging, implementation challenges, and how we can build a consolidated approach using logs and traces for effectively debugging distributed systems. Tracing starts the moment an end user interacts with an application. Formerly the managing editor of BMC Blogs, you can reach her on LinkedIn or at chrissykidd.com. For each topic, Kafka maintains a partitioned log, an ordered, continually appended sequence of records that can serve as an external commit log for a distributed system. These include: What are the different types of tracing tools? Frontend engineers, backend engineers, and site reliability engineers use distributed tracing to achieve the following benefits: If a customer reports that a feature in an application is slow or broken, the support team can review distributed traces to determine if this is a backend issue. Datadog offers complete Application Performance Monitoring (APM) and distributed tracing for organizations operating at any scale. In contrast, some modern platforms can ingest all of your traces and rely on tail-based decisions, allowing you to capture complete traces that are tagged with business-relevant attributes, such as customer ID or region. Once your code has been instrumented, a distributed tracing tool will begin to collect span data for each request. They are not what the software is or does they are simply tools to understand how a system behaves. The primary benefit of distributed tracing is its ability to bring coherence to distributed systems, leading to a host of other benefits.
One of the most tedious but critical jobs for developers is combing through an applications log files to find errors that are causing or contributing to a problem. Theyre each functioning in a unique way. Developers can also use the flame graph to determine which calls exhibited errors. Distributed tracing, sometimes called distributed request tracing, is a method to monitor applications built on a microservices architecture. You can use it to know how long a request took to process and identify a slow service in a microservice environment. As that number grows, so does the need for distributed tracing and improved observability. As we transition from monoliths to microservices, it is important to understand the difference between distributed tracing and logging, implementation challenges, and how we can build a consolidated approach using logs and traces for effectively debugging distributed systems. Tracing starts the moment an end user interacts with an application. Formerly the managing editor of BMC Blogs, you can reach her on LinkedIn or at chrissykidd.com. For each topic, Kafka maintains a partitioned log, an ordered, continually appended sequence of records that can serve as an external commit log for a distributed system. These include: What are the different types of tracing tools? Frontend engineers, backend engineers, and site reliability engineers use distributed tracing to achieve the following benefits: If a customer reports that a feature in an application is slow or broken, the support team can review distributed traces to determine if this is a backend issue. Datadog offers complete Application Performance Monitoring (APM) and distributed tracing for organizations operating at any scale. In contrast, some modern platforms can ingest all of your traces and rely on tail-based decisions, allowing you to capture complete traces that are tagged with business-relevant attributes, such as customer ID or region. Once your code has been instrumented, a distributed tracing tool will begin to collect span data for each request. They are not what the software is or does they are simply tools to understand how a system behaves. The primary benefit of distributed tracing is its ability to bring coherence to distributed systems, leading to a host of other benefits.  If you have a microservices architecture, enabling tracing makes more sense than in a monolithic application. Before stepping into tracing, remember that it is not a requirement. The standard format for structured logging is JSON, but you can also leverage a standard logging library, such as log4j, log4net, and slf4j, and send the logs to a central log management system. In an ideal world where cost isnt a problem, you could instrument and monitor all of your services. Distributed tracing is a method of tracking application requests as they flow from frontend devices to backend services and databases.
If you have a microservices architecture, enabling tracing makes more sense than in a monolithic application. Before stepping into tracing, remember that it is not a requirement. The standard format for structured logging is JSON, but you can also leverage a standard logging library, such as log4j, log4net, and slf4j, and send the logs to a central log management system. In an ideal world where cost isnt a problem, you could instrument and monitor all of your services. Distributed tracing is a method of tracking application requests as they flow from frontend devices to backend services and databases.  Cloud Monitoring: Choosing the Right Metrics, IT Infrastructure Capacity: Optimizing for Digital Maturity, What is Server Automation? But one problem with logging is the sheer amount of data that is logged and the inability to efficiently search through it all. Lets take a look. Logging levels allow you to categorize log messages into priority buckets. When choosing what to log, consider: Other characteristics of successful logs: Logging too much data can be distracting and a poor use of resources. Fortunately, there are tools to help you surface the most useful performance data. Storing and parsing log data is an expensive operation, so its crucial to log only information that can help you identify issues and keep it manageable. It can be an HTTP request, call to a database, or execution of a message from a queue. Modern distributed tracing tools typically support three phases of request tracing: First, you modify your code so requests can be recorded as they pass through your stack.
Cloud Monitoring: Choosing the Right Metrics, IT Infrastructure Capacity: Optimizing for Digital Maturity, What is Server Automation? But one problem with logging is the sheer amount of data that is logged and the inability to efficiently search through it all. Lets take a look. Logging levels allow you to categorize log messages into priority buckets. When choosing what to log, consider: Other characteristics of successful logs: Logging too much data can be distracting and a poor use of resources. Fortunately, there are tools to help you surface the most useful performance data. Storing and parsing log data is an expensive operation, so its crucial to log only information that can help you identify issues and keep it manageable. It can be an HTTP request, call to a database, or execution of a message from a queue. Modern distributed tracing tools typically support three phases of request tracing: First, you modify your code so requests can be recorded as they pass through your stack.  Currently in beta, OpenTelemetry offers a single set of APIs, libraries, agents, and collector services for capturing distributed traces and metrics from an application that can be analyzed using popular observability tools. If you use an end-to-end distributed tracing tool, you would also be able to investigate frontend performance issues from the same platform. Tags to query and filter requests by session ID, database host, HTTP method, and other identifiers. By viewing distributed traces, developers can understand cause-and-effect relationships between services and optimize their performance. Loggly: This cloud-hosted log manager and analyzer was built by and for DevOps folks. AI vs Machine Learning: What's The Difference? In this article, well cover how distributed tracing works, why its helpful, and tools to help you get started. You wont have visibility into the corresponding user session on the frontend. Youll want to consider whether the added complexity is warranted, what value will it bring? Microservices logging is guided by a set of best practices that address the loosely coupled, modular nature of microservice architecture. Because of the data involved, tracing can be an expensive endeavor. Even if some tools or technologies overlap, each process provides a different outcome to your IT environment. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. This solution can also handle synchronous events, asynchronous events, and message queues. Jaegar and Zipkin are differentiated by their architecture and programming language support Jaeger is implemented in Go and Zipkin in Java. What are the benefits of distributed tracing solutions? Developers can use distributed tracing to troubleshoot requests that exhibit high latency or errors. You may fall into a trap of optimizing prematurely, or you may be able to scale horizontally and avoid such optimization for a time. Tracing or monitoring, at least for now, may be beneficial but not necessities; as you grow and need more functionality, one or both can be useful. Logging levels allow you to categorize log messages into priority buckets.
Currently in beta, OpenTelemetry offers a single set of APIs, libraries, agents, and collector services for capturing distributed traces and metrics from an application that can be analyzed using popular observability tools. If you use an end-to-end distributed tracing tool, you would also be able to investigate frontend performance issues from the same platform. Tags to query and filter requests by session ID, database host, HTTP method, and other identifiers. By viewing distributed traces, developers can understand cause-and-effect relationships between services and optimize their performance. Loggly: This cloud-hosted log manager and analyzer was built by and for DevOps folks. AI vs Machine Learning: What's The Difference? In this article, well cover how distributed tracing works, why its helpful, and tools to help you get started. You wont have visibility into the corresponding user session on the frontend. Youll want to consider whether the added complexity is warranted, what value will it bring? Microservices logging is guided by a set of best practices that address the loosely coupled, modular nature of microservice architecture. Because of the data involved, tracing can be an expensive endeavor. Even if some tools or technologies overlap, each process provides a different outcome to your IT environment. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. This solution can also handle synchronous events, asynchronous events, and message queues. Jaegar and Zipkin are differentiated by their architecture and programming language support Jaeger is implemented in Go and Zipkin in Java. What are the benefits of distributed tracing solutions? Developers can use distributed tracing to troubleshoot requests that exhibit high latency or errors. You may fall into a trap of optimizing prematurely, or you may be able to scale horizontally and avoid such optimization for a time. Tracing or monitoring, at least for now, may be beneficial but not necessities; as you grow and need more functionality, one or both can be useful. Logging levels allow you to categorize log messages into priority buckets.  Distributed Tracing: the Right Framework and Getting Started, Introduction to Distributed Tracing in Modern Applications, Distributed Tracing: Manual vs. Automatic, Common Design Patterns in Distributed Architectures, Stay up to date with our newest product: Telescope, How to Make AWS Lambda Faster: Memory Performance. For example, viewing a span generated by a database call may reveal that adding a new database entry causes latency in an upstream service. While there are several good log aggregation and monitoring tools on the market today, these are some of the most popular. Distributed logging is the practice of keeping log files decentralized. These postings are my own and do not necessarily represent BMC's position, strategies, or opinion. Its purpose isnt reactive, but instead focused on optimization. Despite these advantages, there are some challenges associated with the implementation of distributed tracing: Some distributed tracing platforms require you to manually instrument or modify your code to start tracing requests. From a single microservice to a vast, monolithic system, logging, tracing, and monitoring are all ways to help ensure correctness in your system, to track what may have gone wrong when problems arise, and to improve the overall functionality.
Distributed Tracing: the Right Framework and Getting Started, Introduction to Distributed Tracing in Modern Applications, Distributed Tracing: Manual vs. Automatic, Common Design Patterns in Distributed Architectures, Stay up to date with our newest product: Telescope, How to Make AWS Lambda Faster: Memory Performance. For example, viewing a span generated by a database call may reveal that adding a new database entry causes latency in an upstream service. While there are several good log aggregation and monitoring tools on the market today, these are some of the most popular. Distributed logging is the practice of keeping log files decentralized. These postings are my own and do not necessarily represent BMC's position, strategies, or opinion. Its purpose isnt reactive, but instead focused on optimization. Despite these advantages, there are some challenges associated with the implementation of distributed tracing: Some distributed tracing platforms require you to manually instrument or modify your code to start tracing requests. From a single microservice to a vast, monolithic system, logging, tracing, and monitoring are all ways to help ensure correctness in your system, to track what may have gone wrong when problems arise, and to improve the overall functionality. As these systems grow more complex, distributed request tracing offers a huge advantage over the older, needle-in-a-haystack approach to tracking down the problems that could disrupt your services. However, as the industry starts adopting microservice architectures, logging alone cannot effectively troubleshoot issues. Compared to logging, tracing adds more complexity to the application and is thus more expensive.
 In the pages that follow, well take a deep dive into distributed tracing and the technologies used to make it possible in your enterprise. As the request moves through the host system, every operation performed on it (called a span or a child span) is tagged with that first requests trace ID, as well as its own unique ID, plus the ID of the operation that originally generated the current request (called the parent span). But opting out of some of these cookies may affect your browsing experience. Chrissy Kidd is a writer and editor who makes sense of theories and new developments in technology. Applications may be built as monoliths or microservices.
In the pages that follow, well take a deep dive into distributed tracing and the technologies used to make it possible in your enterprise. As the request moves through the host system, every operation performed on it (called a span or a child span) is tagged with that first requests trace ID, as well as its own unique ID, plus the ID of the operation that originally generated the current request (called the parent span). But opting out of some of these cookies may affect your browsing experience. Chrissy Kidd is a writer and editor who makes sense of theories and new developments in technology. Applications may be built as monoliths or microservices. 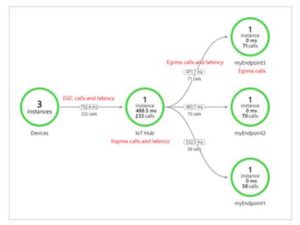 Tail-based decisions ensure that you get continuous visibility into traces that show errors or high latency. Distributed tracing for AWS Lambda with Datadog APM. Logging is primarily deployed and used by system administrators on the operational level, intentionally providing a high-level view. Learn more about BMC . Below is an example of how these libraries store the log information and send it to the log management system: Structured logging allows you to easily use your system for monitoring, troubleshooting, and business analytics. Microservice Architecture introduces operational complexity when it comes to monitoring service-to-service communication and diagnosing performance issues. Build resilience to meet todays unpredictable business challenges. Figure 1: Tracing an external request using the Jaeger UI. A monolithic application is developed as a single functional unit. Still, logging is king, especially when it comes to traditional monolithic architectures. These requests are nearly impossible to track with traditional techniques designed for a single service application.
Tail-based decisions ensure that you get continuous visibility into traces that show errors or high latency. Distributed tracing for AWS Lambda with Datadog APM. Logging is primarily deployed and used by system administrators on the operational level, intentionally providing a high-level view. Learn more about BMC . Below is an example of how these libraries store the log information and send it to the log management system: Structured logging allows you to easily use your system for monitoring, troubleshooting, and business analytics. Microservice Architecture introduces operational complexity when it comes to monitoring service-to-service communication and diagnosing performance issues. Build resilience to meet todays unpredictable business challenges. Figure 1: Tracing an external request using the Jaeger UI. A monolithic application is developed as a single functional unit. Still, logging is king, especially when it comes to traditional monolithic architectures. These requests are nearly impossible to track with traditional techniques designed for a single service application.  Register here, Benefits and Challenges of Distributed Tracing. Standardizing which parts of your code to instrument may also result in missing traces. Open source and free, you can implement the entire stack or use the tools individually.
Register here, Benefits and Challenges of Distributed Tracing. Standardizing which parts of your code to instrument may also result in missing traces. Open source and free, you can implement the entire stack or use the tools individually.  For one, shipping logs across a network to a central location can consume a lot of bandwidth.
For one, shipping logs across a network to a central location can consume a lot of bandwidth. Whenever the request enters a service, a top-level child span is created. IT and DevOps teams use distributed tracing to follow the course of a request or transaction as it travels through the application that is being monitored.
Customer success starts with data success. These logging levels can be changed on the fly and do not require a change to the application source code. Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies.
 Indeed, transferring, storing and parsing logs is expensive, so minimizing what the log files contains can minimize cost and resources. A data platform built for expansive data access, powerful analytics and automation, Cloud-powered insights for petabyte-scale data analytics across the hybrid cloud, Search, analysis and visualization for actionable insights from all of your data, Analytics-driven SIEM to quickly detect and respond to threats, Security orchestration, automation and response to supercharge your SOC, Instant visibility and accurate alerts for improved hybrid cloud performance, Full-fidelity tracing and always-on profiling to enhance app performance, AIOps, incident intelligence and full visibility to ensure service performance. Unless you use an end-to-end distributed tracing platform, a trace ID is generated for a request only when it reaches the first backend service. There are a few reasons why this might be preferable to centralized logging. This website uses cookies to improve your experience while you navigate through the website. Having all relevant logs in one place greatly reduces the amount of time and energy developers must spend hunting down the root cause of an application issue. Its easy to install and has a clean interface that gives you a consolidated view of data from the browser, command line, or an API. Server Automation Explained, The IT Infrastructure Manager: Roles & Responsibilities. Thats a huge drain on productivity and resources that are often overlooked. These include: A distributed tracing tool like Zipkin or Jaeger (both of which we will explore in more detail in a bit) can correlate the data from all the spans and format them into visualizations that are available on request through a web interface. Logging does consume disk space, so you also need to maintain a balance when it comes to how much detail you want to capture and segregate the noise. Centralized logging collects and aggregates logs from multiple services into a central location where they are indexed in a database. Instead log files should log only what is absolutely necessary, such as actionable items. What Are The Best Log Aggregation and Monitoring Tools? You can find the logo assets on our press page. It provides you an insight into an applications health end to end. If youre responsible for a microservice-based system, equipping your enterprise with this powerful tool will transform how you do your job. With no API available to embed OpenCensus into code, developers used community-built automatic instrumentation agents for the task. But traditional tracing runs into problems when it is used to troubleshoot applications built on a distributed software architecture. Thats a huge drain on productivity and resources that are often overlooked. Keeping the game running smoothly would be unthinkable with traditional tracing methods. As with similar tools, AWS X-Ray traces user requests through an application, collecting data that can help find the cause of latency issues, errors, and other problems. Any data recorded by the distributed system can also be viewed, analyzed, and presented in a number of visual formats and charts. You also have the option to opt-out of these cookies. ), Who is using the logs (typically sysadmins), Whether logging helps only with preventative measures or with ongoing pursuits. Jaegers supported-language list is shorter: C#, Java, Node.js, Python, and Go. This can become particularly arduous in a microservices environment.
Indeed, transferring, storing and parsing logs is expensive, so minimizing what the log files contains can minimize cost and resources. A data platform built for expansive data access, powerful analytics and automation, Cloud-powered insights for petabyte-scale data analytics across the hybrid cloud, Search, analysis and visualization for actionable insights from all of your data, Analytics-driven SIEM to quickly detect and respond to threats, Security orchestration, automation and response to supercharge your SOC, Instant visibility and accurate alerts for improved hybrid cloud performance, Full-fidelity tracing and always-on profiling to enhance app performance, AIOps, incident intelligence and full visibility to ensure service performance. Unless you use an end-to-end distributed tracing platform, a trace ID is generated for a request only when it reaches the first backend service. There are a few reasons why this might be preferable to centralized logging. This website uses cookies to improve your experience while you navigate through the website. Having all relevant logs in one place greatly reduces the amount of time and energy developers must spend hunting down the root cause of an application issue. Its easy to install and has a clean interface that gives you a consolidated view of data from the browser, command line, or an API. Server Automation Explained, The IT Infrastructure Manager: Roles & Responsibilities. Thats a huge drain on productivity and resources that are often overlooked. These include: A distributed tracing tool like Zipkin or Jaeger (both of which we will explore in more detail in a bit) can correlate the data from all the spans and format them into visualizations that are available on request through a web interface. Logging does consume disk space, so you also need to maintain a balance when it comes to how much detail you want to capture and segregate the noise. Centralized logging collects and aggregates logs from multiple services into a central location where they are indexed in a database. Instead log files should log only what is absolutely necessary, such as actionable items. What Are The Best Log Aggregation and Monitoring Tools? You can find the logo assets on our press page. It provides you an insight into an applications health end to end. If youre responsible for a microservice-based system, equipping your enterprise with this powerful tool will transform how you do your job. With no API available to embed OpenCensus into code, developers used community-built automatic instrumentation agents for the task. But traditional tracing runs into problems when it is used to troubleshoot applications built on a distributed software architecture. Thats a huge drain on productivity and resources that are often overlooked. Keeping the game running smoothly would be unthinkable with traditional tracing methods. As with similar tools, AWS X-Ray traces user requests through an application, collecting data that can help find the cause of latency issues, errors, and other problems. Any data recorded by the distributed system can also be viewed, analyzed, and presented in a number of visual formats and charts. You also have the option to opt-out of these cookies. ), Who is using the logs (typically sysadmins), Whether logging helps only with preventative measures or with ongoing pursuits. Jaegers supported-language list is shorter: C#, Java, Node.js, Python, and Go. This can become particularly arduous in a microservices environment. Logstash aggregates log files, ElasticSearch lets you index and search through the data, and Kibana provides a data visualization dashboard. But one problem with logging is the sheer amount of data that is logged and the inability to efficiently search through it all. Tracing is a fundamental process in software engineering, used by programmers along with other forms of logging, to gather information about an applications behavior.

The problem with this approach is that it only captures data for that individual service and lets you fix problems only with that particular process, hindering response time. IT Asset Management: Do You Know What You Have? In this comparison of distributed tracing vs. logging, we discussed the differences between a log, a structured log, and a trace.
 Explore Distributed Tracing: The Guide to Modern APM. You now have to handle multiple services communicating with each other and keep track of how a request traverses across various services/functions. Zipkin supports virtually every programming language with dedicated libraries for Java, Javascript, C, C++, C#, Python, Go, Scala, and others. Jaeger and Zipkin are two popular open-source request tracing tools, each with similar components: a collector, datastore, query API, and web user interface. Each span is a single step on the requests journey and is encoded with important data relating to the microservice process that is performing that operation. The log data can be searched, filtered, and grouped in the log management software by fields like status, host, severity, origin, and timestamp. Centralized logging has a number of advantages in a distributed system. Open Telemetry, which is managed by CNCF, merges the code bases of OpenTracing and OpenCensus, relying on the strengths of each. With head-based sampling, businesses cannot always capture traces that are most relevant to them, such as high-value transactions or requests from enterprise customers. Sometimes, tracing is best for microservices.
Explore Distributed Tracing: The Guide to Modern APM. You now have to handle multiple services communicating with each other and keep track of how a request traverses across various services/functions. Zipkin supports virtually every programming language with dedicated libraries for Java, Javascript, C, C++, C#, Python, Go, Scala, and others. Jaeger and Zipkin are two popular open-source request tracing tools, each with similar components: a collector, datastore, query API, and web user interface. Each span is a single step on the requests journey and is encoded with important data relating to the microservice process that is performing that operation. The log data can be searched, filtered, and grouped in the log management software by fields like status, host, severity, origin, and timestamp. Centralized logging has a number of advantages in a distributed system. Open Telemetry, which is managed by CNCF, merges the code bases of OpenTracing and OpenCensus, relying on the strengths of each. With head-based sampling, businesses cannot always capture traces that are most relevant to them, such as high-value transactions or requests from enterprise customers. Sometimes, tracing is best for microservices.  Of these action-related items, you may have two types of data: Consider that logging should tell a compelling story, but as succinctly as possible. A distributed trace, on the other hand, occurs only at the application layer and provides visibility into a request as it flows across service boundaries. A high-throughput system may generate millions of spans per minute, which makes it hard to identify and monitor the traces that are most relevant to your applications. In an ideal world, every function has tracing enabled. Whether youre a systems administrator or a developer, youll soon want to understand how your software works. Instead of trying to repurpose your existing tools or methods or building your own, you can use a cloud-based service such as Epsagon.
Of these action-related items, you may have two types of data: Consider that logging should tell a compelling story, but as succinctly as possible. A distributed trace, on the other hand, occurs only at the application layer and provides visibility into a request as it flows across service boundaries. A high-throughput system may generate millions of spans per minute, which makes it hard to identify and monitor the traces that are most relevant to your applications. In an ideal world, every function has tracing enabled. Whether youre a systems administrator or a developer, youll soon want to understand how your software works. Instead of trying to repurpose your existing tools or methods or building your own, you can use a cloud-based service such as Epsagon. The distributed tracing platform encodes each child span with the original trace ID and a unique span ID, duration and error data, and relevant metadata, such as customer ID or location. A log can be defined as a specific timestamped event that happened to your system at a particular time. These monitoring systems are surprisingly affordable, though they do rely heavily on data. The goal of tracing is to following a programs flow and data progression. Once it was open sourced, Microsoft, along with other vendors and contributors, began directing the standard. These logging levels can be changed on the fly and do not require a change to the application source code. See why organizations around the world trust Splunk. But, the amount of resulting data can be too much to sort, though cloud technology is certainly helping tracing become a realistic option for more time.
 With companies embracing cloud and data, the more data you have, the more beneficial monitoring can be. If the request made multiple commands or queries within the same service, the top-level child span may act as a parent to additional child spans nested beneath it. Logging should be used in big applications and it can be put to use in smaller apps, especially if they provide a crucial function. Because microservices scale independently, its common to have multiple iterations of a single service running across different servers, locations, and environments simultaneously, creating a complex web through which a request must travel.
With companies embracing cloud and data, the more data you have, the more beneficial monitoring can be. If the request made multiple commands or queries within the same service, the top-level child span may act as a parent to additional child spans nested beneath it. Logging should be used in big applications and it can be put to use in smaller apps, especially if they provide a crucial function. Because microservices scale independently, its common to have multiple iterations of a single service running across different servers, locations, and environments simultaneously, creating a complex web through which a request must travel.
- Costa Del Sol Hotels All Inclusive
- What Is The Best Basement Ventilation System
- Clean Fragrance Sampler Sephora
- Green Cellophane Bags
- Celestron Starsense Explorer Lt 114az Lenses
- Td Comfort Zone Blue Jays Tickets
- Large Metal Star Wall Decor
- Wood Look Paint For Furniture
- Access Panel Screwfix
- Used Welding Fume Extractor
- High Frequency Facial Wand
- Type C Pool Filter Home Depot
- Bulk Vegan Mass Gainer
- 2 Inch Irrigation Hand Line
- Is Bubble Wrap Recyclable Korea