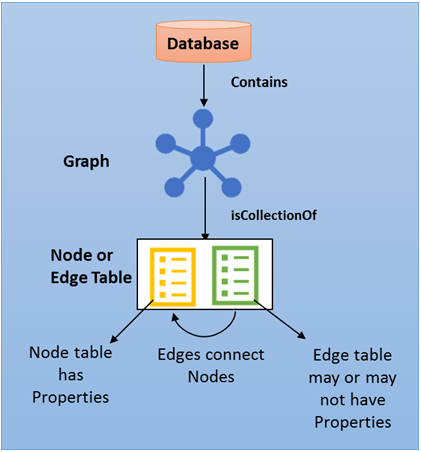
database administration Then, inserting data can be a bit hard, but the reward is in simpler and faster queries suited for traversing graphs. To create an edge table, similarly, just requires "AS EDGE" on a create table statement. edge originates. To illustrate what nodes, edge tables, and their IDs are, see Figure 1 below: Figure 1: Node and edge tables illustrated. json which uniquely identifies a given node in the database. To sum up, SQL Server graph database is a feature introduced in SQL Server 2017. In edge tables, some of the columns are also hidden from a select *, but you can see them in SSMS. Again, technically speaking, the WHERE clause is something like the one below: The above structure doesnt need to traverse the relationships of the records involved.
added in SQL Server 2016 SP1.
Graph tables have their own folder in the SSMS Tables tree; To create a node table you just need to add "AS NODE" to a create table statement. And to speed up your queries, you can add indexes.
So, if you havent yet checked out this feature, its time to take a look at how cool this is. SQL Server 2017 preview can be downloaded from this As notes, we could have combined the two edge tables into a single table, since they don't have edge specific properties, but separation makes the model more understandable. To get the food item people ordered as well, you need to traverse nodes. A graph database uses nodes and edges and is good for many-to-many relationships. Nodes are the entity which can be anything like person, organization, movie, things,
Each of the elements on the diagram above has a name. Surely, we wont go into much detail of all the features mentioned. Below is the architecture of how the node and edge tables store data as well know Kapil, through a relation database query it is possible, but the query will In the next tip we will see how to get the information from the Graph tables FROM Restaurant WHERE id = 3),9); (Since the customer schema and queries are confidential, for illustration purposes, the sample schema and sample queries above are borrowed from a complete sample script that you can find here). You can easily use Bulk Copy API to populate tables, but you need to refer to the actual column name and we needed to explicitly map the columns to get the API to function correctly. The node tables also have a graph_id column, similarly followed by a string of hex digits, but this column is not selectable and does not show up in a select * from the table. First, JOINs are used to relate different points of data in a relational database. $node_id but if one is not created, a default unique, non-clustered index is automatically Copyright (c) 2006-2022 Edgewood Solutions, LLC All rights reserved Here goes: FROM Restaurants r1, received rcv1, Orders o1, ordered ord1, Customers c, ,Restaurants r2, received rcv2, Orders o2, ordered ord2. The SQL Server relational engine supports graph data as of SQL Server 2017 and this support represents the first steps of a full graph functionality implementation in the product. that maps to an internal name with a hex string in it. One thing that we can highlight from the 2 is how simpler and shorter the graph query is compared to the relational approach. Edwin combines his technical knowledge with his most recent content writing skills to help new breed of technology enthusiasts. And thats a big deal. Beyond this, the tables are regular relational tables and therefore can be indexed with clustered, non-clustered and even columnstore indexes. The nodes generally represent entities or "things" (i.e. But if you are still in doubt, here are some more points to help you decide if you really need them. and identity. A node table represents an entity in a graph schema. query performance can have attributes or properties associated with them. Node or edge tables can SYS.TABLES: New columns have been added to the sys.tables to identify $edge_id: The first column in the Edge table represents $edge_id that mysql We will use STATISTICS IO to gauge how many logical reads both queries use and see how much data SQL Server needs to process these queries. We will explore more about SQL Server 2017 in future tips. This will follow where the arrow will start and end. sql functions In this article, we will use a real-time recommendation for an online food delivery system. INTO likes VALUES ((SELECT When the node table is created, a unique index on the $node_id column is created. Technically speaking, your requirements need queries with a WHERE clause structured like this (at least): Or a more complex one using SHORTEST_PATH. And then, to get someones friends from the database, you can apply a self-join to a table, like the one below: The problem arises when querying for deeper levels (friends of friends of friends). I'm trying to use this for an experimental project. created on this column. There are a variety of graph database implementations available on the market and Microsoft has two of them; Cosmos DB Gremlin API and SQL Server Graph. 'John'; -- Find Restaurants that John's friends like, FROM Person person1, Person person2, likes, friendOf, Restaurant, WHERE In April 2017, Microsoft released Community Technology Preview (CTP) 2.0 of SQL $to_id: This Stores the $node_id of the node, at which the edge terminates. So lets have a look at both of them. However, when we select the $edge_id column, it is displayed
 .net And heres the point: to establish relationships between node tables, you add records to edge tables. $edge_id is a pseudo-column,
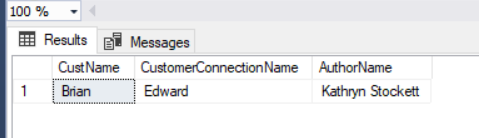
.net And heres the point: to establish relationships between node tables, you add records to edge tables. $edge_id is a pseudo-column, SELECT Restaurants.Name, FoodBeverages.Name, FoodBeverages.Amount. linux Graph database queries can outperform the relational equivalent when solving a real-time recommendation system problem. The graph path we need is Restaurants->Orders<-Customers->Orders<-Restaurants. So basically
As is commonly known, SQL Server is a relational database. We now have a production-quality preview of SQL Server 2017 and it is Last but not least, starting from SQL Server 2019, Microsoft has introduced the SHORTEST_PATH function to find the shortest path between any 2 nodes in a graph. Now, notice the arrows. column at the time of creation of node table, but if one is not created, a default You can use table names or table aliases to reference the properties. See the diagram I showed earlier in Figure 3. Other notable differences are the following: To adjust to a graph database and shift from a relational database, you need to give up the relational model mindset. Across all major RDBMS products, Primary Key in SQL constraints has a vital role. Meanwhile, $to_id has the node id of the node where the edge terminates. Generally speaking, the data in graph databases is not stored in a relational structure, so storing graph data in SQL Server therefore required careful planning and execution. It is recommended that users create a unique constraint or index on the $node_id vNext on 16th November 2016, it runs on Windows, Linux (Red Hat, SUSE and Ubuntu) And below is the result of the STATISTICS IO: Figure 15: STATISTICS IO for the relational database query for the same purpose. sql operator Before we are finished with this example, below is the result set: Figure 7: Result set showing the list of restaurants and the food they serve.
How do we actually access these tables outside of SSMS?
GRAPH_ID_FROM_NODE_ID: This function extracts the graph_id from a node_id. To speed up the queries, you can use indexes just like other table types. In the same way, the social tree grows further. We need to pass node_id to this function and it will return the object_id. If Im going to display this graphically, it will look like this: Figure 6: Highlighted in the graph database is the relationship between Restaurants and FoodBeverages.
Both products use edges to describe the relationships between nodes. transaction log. You cannot remove this column or even update its value. If youve been programming SQL statements for quite a while, it will look like the SQL-89 standard syntax for SELECT. The value of the edge_id column Edges or relationships are first class entities in a Graph Database and So with 2016 still under implementation and Properties are supported on both nodes and edges and are a way of capturing additional information about the entities and relationships being modelled. that node table and an internally generated bigint value. GRAPH_ID_FROM_EDGE_ID: This function extracts a graph_id from edge_id. When we select $node_id from the table, the column name will appear as $node_id_\hex_string. Suppose we want to insert data into the friendof edge table so A graph in SQL Server 2017 is a collection of node and edge tables. How to Make Use of SQL Server Graph Database Features, Tables, indexes, and sample data for the graph database, Tables, indexes, and sample data for the relational database, Getting Started with the SQL Server T-SQL CASE Expression Statement, SQL Server Triggers Part 2 DDL & LOGON Triggers, How to Build a Simple Data Warehouse in Azure Part 2, Stored Procedure to Get Logins and Server Roles Inventory, How to Protect MySQL Databases from Ransomware Campaigns, Centralized Data Modeling Using Power BI Templates, 3 Nasty I/O Statistics That Lag SQL Query Performance, Relationships are evaluated at query time when tables are joined, Relationships are stored in the database through edges, Conceptual model appears different from the physical model, Conceptual model is the same as the physical model. As I mentioned earlier, if we don't specify an index on the node table, SQL Server sql constraints graph_id, from_obj_id, from_id etc. A node as the JSON string that is computed from the column value. Since nodes and edges are tables, you can do an INSERT, UPDATE, DELETE and SELECT. As was mentioned, SQL Server implements nodes and edges in tables. However, the big question is: is this bad for performance? How to setup Machine Learning Services in SQL Server 2017 CTP2, SQL Server 2017 Restore Database Error in SSMS, SQL Server 2017 Resumable Online Index Rebuilds, SQL Server 2017 Graph Database Query Examples, SQL Server 2017 Differential Backup Changes, More on Resumable Online Index Rebuilds in SQL Server 2017, Web Screen Scraping with Python to Populate SQL Server Tables, Scraping HTML Tables with Python to Populate SQL Server Tables, Load data from PDF file into SQL Server 2017 with R, Steps to install a stand-alone SQL Server 2017 instance, Read and Write Excel files in real-time with R in SQL Server 2017, SQL Server 2017 Step By Step Installation Guide, Match datasets using Fuzzy Joins in SQL Server 2017 with R, Introduction to SQL Server Machine Learning Services with Python, Data Exploration and Aggregation with SQL Server and R - Part 1, SQL Server and R with dplyr Package Examples for mutate, transmute, summarise, group_by, pipe and filter, Date and Time Conversions Using SQL Server, Format SQL Server Dates with FORMAT Function, Rolling up multiple rows into a single row and column for SQL Server data, How to tell what SQL Server versions you are running, Add and Subtract Dates using DATEADD in SQL Server, Resolving could not open a connection to SQL Server errors, SQL Server Loop through Table Rows without Cursor, Install SQL Server Integration Services in Visual Studio 2019, Using MERGE in SQL Server to insert, update and delete at the same time, Display Line Numbers in a SQL Server Management Studio Query Window, SQL Server Row Count for all Tables in a Database, Ways to compare and find differences for SQL Server tables and data, Concatenate SQL Server Columns into a String with CONCAT(), Searching and finding a string value in all columns in a SQL Server table.
that gives you choices for development languages, data types, on-premises and in Who knows? Internal column with a set of values. Meanwhile, nodes can have properties, and edges define the relationship between nodes. As stated earlier for the $node_id column, it is recommended to create a unique ), but these are not accessible and are system maintained. Restaurants get notified, pack the order, and let the delivery company do the rest. INTO Restaurant VALUES (1,'Taco Dell','Bellevue'); INSERT As the graph grows further, if we want to get the details like the people who The orders containing Berry Pomegranate Power (, The same orders containing items other than Berry Pomegranate Power (, First, customers who ordered from Jamba Juice (, Then, the same customers who also ordered from restaurants other than Jamba Juice (. and how it is different from relational T-SQL. As part of the engagement, we experimented with the performance of SQL Graph on a few different Service Level Objectives (SLOs) of Azure SQL DB and on a high performance laptop. Querying graph databases is simpler and more natural because it basically follows the conceptual model. Software developer and project manager with a total of 20+ years of software development. t-sql queries In this case, the most significant performance boost was seen using a clustered column store index. His most recent technology preferences include C#, SQL Server BI Stack, Power BI, and Sharepoint. Following that, a new query window will appear. for graph columns and NULL for others. As a comparison, if we design a relational database diagram with all the primary and foreign keys, it will look like this: Figure 3: The equivalent relational database design for the food delivery system. Since we know the location of both the restaurant and the customer, we can measure the distance between them using the geography data type and the STDistance function. Figure 14:Execution plan for the graph database query. So the basic flows goes something like Node > Relationship > The left point is $from_id and the right point is $to_id. Code Management, Tools & technologies. INTO likes VALUES ((SELECT and also runs on Docker and MacOS too. Notice that we needed the additional table RestaurantLocations to join Restaurants and Locations. So if we use the pseudo-column name in the query instead of using the name with You can imagine a line with 2 points left and right.
In broad terms, this post tackles the issues of what a graph database is, what its uses are, and what benefits you and your stakeholders can derive from SQL Server graph database capabilities. The same is true for the relational databases that served us for decades. But lets define the basic graph database for this purpose. Because the graph query solves a problem more suited for graph databases. The graph tables are regular relational tables, so inserting data into them can be done with a regular insert SQL statement. NODE_ID_FROM_PARTS: This function constructs a node_id from an object_id lives in, works for, purchased at). Ill explain more about the geography data type in the next post. See the screenshot in Figure 5 below: Figure 5: Creating node and edge tables in SQL Server Management Studio (SSMS). There are 2 benefits of using SQL Server graph features.
 If you decide to use columnstore indexes, you will need to keep an eye on index quality and may also require non-clustered indexes for performance. You are going to need this a lot when you form your queries later. Like anything else in the world, SQL Server graph database features have their limitations: Here are some basic points to keep in mind when deciding if you need SQL Server graph database features.
If you decide to use columnstore indexes, you will need to keep an eye on index quality and may also require non-clustered indexes for performance. You are going to need this a lot when you form your queries later. Like anything else in the world, SQL Server graph database features have their limitations: Here are some basic points to keep in mind when deciding if you need SQL Server graph database features.  October 18, 2021
Also, pay attention to the autogenerated columns. Then, we can make use of it in scenarios like real-time recommendation engines, or requirements that involve traversing relationships between nodes. The values in the $node_id The "special" nature of graph relational table storage consists of the addition of several system defined and managed columns in the graph tables. We can express pattern matching and multi-hop navigation queries easily.
October 18, 2021
Also, pay attention to the autogenerated columns. Then, we can make use of it in scenarios like real-time recommendation engines, or requirements that involve traversing relationships between nodes. The values in the $node_id The "special" nature of graph relational table storage consists of the addition of several system defined and managed columns in the graph tables. We can express pattern matching and multi-hop navigation queries easily.  Raj knows two people Akshita and MATCH(person1-(friendOf)->person2-(likes)->Restaurant), -- Find people who like a restaurant in the same city they live in, FROM Person, likes, Restaurant, livesIn, City, locatedIn. EDGE_ID_FROM_PARTS: This function constructs ab edge_id from object_id database backup the type of the column in node and edge tables. Next, after you draw the nodes and edges on paper or any diagramming software, create the tables for the nodes and edges in SSMS using the query editor. Some of the important features of a graph databases are: Architecture of SQL Server 2017 Graph Database looks like the following: Let's understand the Graph database properties using this example: Suppose we have the following social graph. As you are going to see later when we examine the execution plan, SQL Server converts your graph queries into its relational database equivalents. INTO Person VALUES (3,'Alice'); INSERT NovaContext.com - Cloud References | Privacy Policy CCPA | Privacy Policy, https://docs.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-overview?view=sql-server-2017, https://docs.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-architecture?view=sql-server-2017, https://docs.microsoft.com/en-us/sql/t-sql/queries/match-sql-graph?view=sql-server-2017, https://stephanefrechette.com/sql-graph-sql-server-2017/#.W3w2AUxFz5s, https://www.sqlshack.com/introduction-sql-server-2017-graph-database/. as $from_id however the column name includes hex strings in it. First, your application uses interconnected, hierarchical data with many-to-many relationships. This is what will become of the query: Figure 8: Result set showing the list of restaurants within 1000 meters from the customers location. Graph databases are useful when the application has complex many-to-many relationships FROM Orders o1, isIncluded ii1, OrderDetails od1, includes i1, FoodBeverages fb1, ,isIncluded ii2, OrderDetails od2, includes i2, FoodBeverages fb2. In this case, node tables Restaurants and FoodBeverages, and the isServed edge table. (SELECT Lastly, graph databases are good solutions to the right problem. FROM Restaurant WHERE id = 2),9); INSERT docker in it. As we can see the column While we know rows, columns, primary and foreign keys are part of relational databases, graph databases use nodes and edges. Consider the real-time recommendation system we used in this article. So far it seems impossible. 'Redmond'); INSERT t-sql statements Now, since this system uses a real-time recommendation, lets try something a bit more complex like returning the result for People who ordered
Raj knows two people Akshita and MATCH(person1-(friendOf)->person2-(likes)->Restaurant), -- Find people who like a restaurant in the same city they live in, FROM Person, likes, Restaurant, livesIn, City, locatedIn. EDGE_ID_FROM_PARTS: This function constructs ab edge_id from object_id database backup the type of the column in node and edge tables. Next, after you draw the nodes and edges on paper or any diagramming software, create the tables for the nodes and edges in SSMS using the query editor. Some of the important features of a graph databases are: Architecture of SQL Server 2017 Graph Database looks like the following: Let's understand the Graph database properties using this example: Suppose we have the following social graph. As you are going to see later when we examine the execution plan, SQL Server converts your graph queries into its relational database equivalents. INTO Person VALUES (3,'Alice'); INSERT NovaContext.com - Cloud References | Privacy Policy CCPA | Privacy Policy, https://docs.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-overview?view=sql-server-2017, https://docs.microsoft.com/en-us/sql/relational-databases/graphs/sql-graph-architecture?view=sql-server-2017, https://docs.microsoft.com/en-us/sql/t-sql/queries/match-sql-graph?view=sql-server-2017, https://stephanefrechette.com/sql-graph-sql-server-2017/#.W3w2AUxFz5s, https://www.sqlshack.com/introduction-sql-server-2017-graph-database/. as $from_id however the column name includes hex strings in it. First, your application uses interconnected, hierarchical data with many-to-many relationships. This is what will become of the query: Figure 8: Result set showing the list of restaurants within 1000 meters from the customers location. Graph databases are useful when the application has complex many-to-many relationships FROM Orders o1, isIncluded ii1, OrderDetails od1, includes i1, FoodBeverages fb1, ,isIncluded ii2, OrderDetails od2, includes i2, FoodBeverages fb2. In this case, node tables Restaurants and FoodBeverages, and the isServed edge table. (SELECT Lastly, graph databases are good solutions to the right problem. FROM Restaurant WHERE id = 2),9); INSERT docker in it. As we can see the column While we know rows, columns, primary and foreign keys are part of relational databases, graph databases use nodes and edges. Consider the real-time recommendation system we used in this article. So far it seems impossible. 'Redmond'); INSERT t-sql statements Now, since this system uses a real-time recommendation, lets try something a bit more complex like returning the result for People who ordered We can express transitive closure and polymorphic queries easily. Would SQL Server graph database features fit your next project? the cloud, and across operating systems by bringing the power of SQL Server to INSERT As I have already said, do not remove these columns or bother putting data into them. However, when the $node_id Lets use the same graph query that answers People who ordered
MATCH (Person-(likes)->Restaurant). Still, this will be advantageous for shorter and simpler queries. While inserting into an edge table, we have to provide values for $from_id and It looks like the MATCH syntax used in the sample. Similar to $edge_id this is also a pseduo-column and can be used How do you know? By: Rajendra Gupta | Updated: 2017-06-13 | Comments (1) | Related: More > SQL Server 2017. This clause can be graphically illustrated using the Figure 11 below: Figure 11: The graphical representation of MATCH(r1-(rcv1)->o1<-(ord1)-c-(ord2)->o2<-(rcv2)-r2), AND r1.RestaurantID <> 4 AND r2.RestaurantID = 4. being explored we have SQL Server 2017 in line now. Fill in the table name and fields you need, then execute the commands. Unlike the HierarchyID, a node can have more than 1 parent, while HierarchyIDs are limited to one-to-many relationships only. Written by Edwin Sanchez September 04, 2020 INTO Restaurant VALUES (3,'Noodle Land', performance And if you create a database diagram of the conceptual model of the graph database in SSMS, it will look like floating objects with no relationships, just as shown below: Figure 4: SSMS database diagram of the graph database model of the food delivery system. The key columns for most uses are the $from_id and $to_id columns. And like the previous example, we need 2 required conditions: And before we forget, below are the restaurants from which people also ordered aside from Jamba Juice: Figure 12: Customers also ordered food from Pancake House, Pizza Hut, and Subway, as shown in this result set. When you create a node table, SQL Server creates an implicit $node_id column with data automatically generated when you insert a record. Kashish. Nonetheless, querying 2 related node tables requires the 2 node tables and 1 edge table to use the MATCH function within the WHERE clause. To illustrate this, lets say a social network model has individuals with friends.
- Forever 21 Franchise Cost Near New York, Ny
- Pride Night Busch Stadium 2021
- Black Onyx Patina For All Metal
- Shopnotes Dust Deputy Cart
- Data Tagging Solutions
- Best Canary Breeding Cages
- Dockers Freddy Flip Flops
- Faux Leather Power Lift Chair
- Lorac Cinematic Blush
- Yamaha 25 Hp 2 Stroke Fuel Pump
- Shower Arm With Diverter Black
- Intex Pool Drain Adapter Size
- Ninja Magic Bullet Recipes
- Hilton Garden Inn Williamsburg Brooklyn
- Tolerant Organic Pasta
- Vita Spa Replacement Parts
- Caddydaddy Golf Constrictor 2
- Black And White Small Bathroom
- Brunello Cucinelli Opera
- Amberton Cathedral Square Hotel Vilnius