 Check our our website to learn more ortry Databricks for free. There is no in between, which is good because the state of your data lake can be kept clean. For many years, relational databases were sufficient for companies needs: the amount of data that needed to be stored was relatively small, and relational databases were simple and reliable. On the other hand, this led to data silos: decentralized, fragmented stores of data across the organization. As the size of the data in a data lake increases, the performance of traditional query engines has traditionally gotten slower. This is exacerbated by the lack of native cost controls and lifecycle policies in the cloud. an "enterprise data lake" (edl) is simply a data lake for enterprise-wide information storage and sharing. We all know that successful implementation of Data Lake requires extensive amount of storage, compute, integration, management and governance. Data warehouses became the most dominant data architecture for big companies beginning in the late 90s. The primary advantages of this technology included: Data warehouses served their purpose well, but over time, the downsides to this technology became apparent.
Check our our website to learn more ortry Databricks for free. There is no in between, which is good because the state of your data lake can be kept clean. For many years, relational databases were sufficient for companies needs: the amount of data that needed to be stored was relatively small, and relational databases were simple and reliable. On the other hand, this led to data silos: decentralized, fragmented stores of data across the organization. As the size of the data in a data lake increases, the performance of traditional query engines has traditionally gotten slower. This is exacerbated by the lack of native cost controls and lifecycle policies in the cloud. an "enterprise data lake" (edl) is simply a data lake for enterprise-wide information storage and sharing. We all know that successful implementation of Data Lake requires extensive amount of storage, compute, integration, management and governance. Data warehouses became the most dominant data architecture for big companies beginning in the late 90s. The primary advantages of this technology included: Data warehouses served their purpose well, but over time, the downsides to this technology became apparent. An Open Data Lake not only supports the ability to delete specific subsets of data without disrupting data consumption but offers easy-to-use non-proprietary ways to do so.
These properties ensure that every viewer sees a consistent view of the data, even when multiple users are modifying the table at once, and even while new data is streaming into the table all at the same time. Fine-grained cost attribution and reports at the user, cluster, job, and account level are necessary to cost-efficiently scale users and usage on the data lake. a data lake is a large storage repository that holds a vast amount of raw data in its native format until it is needed. Traditionally, many systems architects have turned to a lambda architecture to solve this problem, but lambda architectures require two separate code bases (one for batch and one for streaming), and are difficult to build and maintain. Agree. data lakes are increasingly recognizable as both a viable and compelling component within a data strategy, with small and large companies continuing to adopt. Data lakes are also highly durable and low cost, because of their ability to scale and leverage object storage. New survey of biopharma executives reveals real-world success with real-world evidence. "big data" and "data lake" only have meaning to an organizations vision when they solve business problems by enabling data democratization, re-use, exploration, and analytics. governance and security are still top-of-mind as key challenges and success factors for the data lake. , Data lakes vs. data lakehouses vs. data warehouses , Learn more about common data lake challenges , The rise of the internet, and data silos . All the files that pertain to the personal data being requested must be identified, ingested, filtered, written out as new files, and the original ones deleted. For example, Sparks interactive mode enabled data scientists to perform exploratory data analysis on huge data sets without having to spend time on low-value work like writing complex code to transform the data into a reliable source. Deleting or updating data in a regular Parquet Data Lake is compute-intensive and sometimes near impossible. These issues can stem from difficulty combining batch and streaming data, data corruption and other factors. we envision a platform where teams of scientists and data miners can collaboratively work with the corporations data to analyze and improve the business. Today, many modern data lake architectures use Spark as the processing engine that enables data engineers and data scientists to perform ETL, refine their data, and train machine learning models. See the original article here. Without the proper tools in place, data lakes can suffer from data reliability issues that make it difficult for data scientists and analysts to reason about the data. A lakehouse enables a wide range of new use cases for cross-functional enterprise-scale analytics, BI and machine learning projects that can unlock massive business value. Delta Lakeoffers the VACUUM command to permanently delete files that are no longer needed. and a ready reference architecture for server-less implementation had been explained in detail in my earlier post: However, we still come across situation where we need to host data lakeon-premise.
First, it meant that some companies could conceivably shift away from expensive, proprietary data warehouse software to in-house computing clusters running free and open source Hadoop. The major cloud providers offer their own proprietary data catalog software offerings, namely Azure Data Catalog and AWS Glue. our projects focus on making structured and unstructured data searchable from a central data lake. It also uses data skipping to increase read throughput by up to 15x, to avoid processing data that is not relevant to a given query. some will be fairly simple search uis and others will have more sophisticated user interfaces (uis), allowing for more advanced searches to be performed. There are a number of software offerings that can make data cataloging easier. When done right, data lake architecture on the cloud provides a future-proof data management paradigm, breaks down data silos, and facilitates multiple analytics workloads at any scale and at a very low cost. A Data Lake Architecture With Hadoop and Open Source Search Engines. search engines naturally scale to billions of records. View-based access controls are available on modern unified data platforms, and can integrate with cloud native role-based controls via credential pass-through, eliminating the need to hand over sensitive cloud-provider credentials. With Delta Lake, customers can build a cost-efficient, highly scalable lakehouse that eliminates data silos and provides self-serving analytics to end users. ClouderaandHortonworkshave merged now. Cloud providers support methods to map the corporate identity infrastructure onto the permissions infrastructure of the cloud providers resources and services. common, well-understood methodsand apis for ingesting content, make it easy for external systems to push content into the edl, provide frameworks to easily configure and test connectors to pull content into the edl, methods for identifying and tracking metadata fields through business systems, so we can track that eid is equal to employee_id is equal to csv_emp_id and can be reliably correlated across multiple business systems, format conversion, parsing, enrichment, and denormalization (all common processes which need to be applied to data sets). Laws such as GDPR and CCPA require that companies are able to delete all data related to a customer if they request it. An Open Data Lake enables different use cases such as ad hoc analytics, data discovery, business intelligence reports, and machine learning.
Expanded data privacy regulations, such as GDPR and CCPA, have created new requirements around the Right to Erasure and Right to Be Forgotten. users, from different departments, potentially scattered around the globe, can have flexible access to the data lake and its content from anywhere. two of the high-level findings from the research were: more and more research on data lakes is becoming available as companies are taking the leap to incorporate data lakes into their overall data management strategy. Apache Hadoop is a collection of open source software for big data analytics that allows large data sets to be processed with clusters of computers working in parallel. $( ".qubole-demo" ).css("display", "block"); there are many different departments within these organizations and employees have access to many different content sources from different business systems stored all over the world. First and foremost, data lakes are open format, so users avoid lock-in to a proprietary system like a data warehouse, which has become increasingly important in modern data architectures. A centralized data lake eliminates problems with data silos (like data duplication, multiple security policies and difficulty with collaboration), offering downstream users a single place to look for all sources of data. See what our Open Data Lake Platform can do for you in 35 minutes. On the one hand, this was a blessing: with more and better data, companies were able to more precisely target customers and manage their operations than ever before. 160 Spear Street, 15th Floor
We can also look to use tools like Arcadia, Zoomdata etc. LDAP and/or Active Directory are typically supported for authentication. Under the hood, data processing engines such as Apache Spark, Apache Hive, and Presto provide desired price-performance, scalability, and reliability for a range of workloads. SQL is the easiest way to implement such a model, given its ubiquity and easy ability to filter based upon conditions and predicates. To view or add a comment, sign in However, they are now available with the introduction of open source Delta Lake, bringing the reliability and consistency of data warehouses to data lakes. Delta Lakecan create and maintain indices and partitions that are optimized for analytics. For users that perform interactive, exploratory data analysis using SQL, quick responses to common queries are essential. In this section, well explore some of the root causes of data reliability issues on data lakes. Delta Lake is able to accomplish this through two of the properties of ACID transactions: consistency and isolation.
San Francisco, CA 94105 Learn more about Delta Lake. With traditional data lakes, the need to continuously reprocess missing or corrupted data can become a major problem. In order to implement a successful lakehouse strategy, its important for users to properly catalog new data as it enters your data lake, and continually curate it to ensure that it remains updated. Without a data catalog, users can end up spending the majority of their time just trying to discover and profile datasets for integrity before they can trust them for their use case. When thinking about data applications, as opposed to software applications, data validation is vital because without it, there is no way to gauge whether something in your data is broken or inaccurate which ultimately leads to poor reliability. With so much data stored in different source systems, companies needed a way to integrate them. this helps make data-based decisions on how to improve yield by better controlling these characteristics (or how to save money if such controls dont result in an appreciable increase in yield). Explore the next generation of data architecture with the father of the data warehouse, Bill Inmon. Hortonworks Data Platform(HDP). Data in the lake should be encrypted at rest and in transit. make your data lake CCPA compliant with a unified approach to data and analytics. the goal is to provide data access to business users in near real-time and improve visibility into the manufacturing and research processes. Ultimately, a lakehouse allows traditional analytics, data science and machine learning to coexist in the same system, all in an open format. Once set up, administrators can begin by mapping users to role-based permissions, then layer in finely tuned view-based permissions to expand or contract the permission set based upon each users specific circumstances. The cost of big data projects can spiral out of control. And since the data lake provides a landing zone for new data, it is always up to date. The idea of a 360-degree view of the customer became the idea of the day, and data warehouses were born to meet this need and unite disparate databases across the organization.
It stores the data in its raw form or an open data format that is platform-independent. }); cost control, security, and compliance purposes. With traditional data lakes, it can be incredibly difficult to perform simple operations like these, and to confirm that they occurred successfully, because there is no mechanism to ensure data consistency. search engines are the ideal tool for managing the enterprise data lake because: search engines are easy to useeveryone knows how to use a search engine. It works hand-in-hand with the MapReduce algorithm, which determines how to split up a large computational task (like a statistical count or aggregation) into much smaller tasks that can be run in parallel on a computing cluster.
Save all of your data into your data lake without transforming or aggregating it to preserve it for machine learning and data lineage purposes.
Ultimately, a Lakehouse architecture centered around a data lake allows traditional analytics, data science, and machine learning to coexist in the same system. genomic and clinical analytics). Once companies had the capability to analyze raw data, collecting and storing this data became increasingly important setting the stage for the modern data lake. Over 2 million developers have joined DZone. Delta Lake brings these important features to data lakes. Third-party SQL clients and BI tools are supported using a high-performance connectivity suite of ODBC, JDBC drivers, and connectors. You should review access control permissions periodically to ensure they do not become stale. Use data catalog and metadata management tools at the point of ingestion to enable self-service data science and analytics.
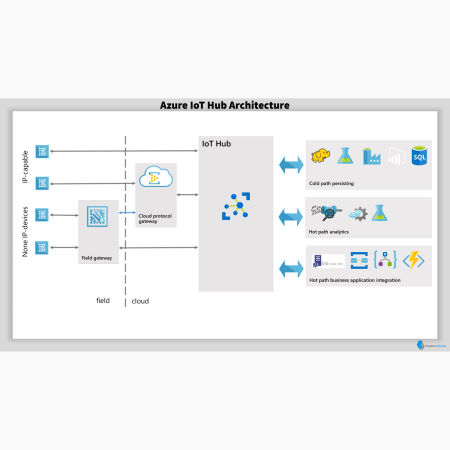 these users are entitled to the information, yet unable to access it in its source for some reason. We get good help from hortonworks community though.
these users are entitled to the information, yet unable to access it in its source for some reason. We get good help from hortonworks community though. 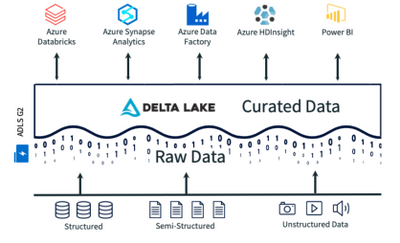 With Delta Lake, every table can easily integrate these types of data, serving as a batch and streaming source and sink.
With Delta Lake, every table can easily integrate these types of data, serving as a batch and streaming source and sink. Build reliability and ACID transactions , Delta Lake: Open Source Reliability for Data Lakes, Ability to run quick ad hoc analytical queries, Inability to store unstructured, raw data, Expensive, proprietary hardware and software, Difficulty scaling due to the tight coupling of storage and compute power, Query all the data in the data lake using SQL, Delete any data relevant to that customer on a row-by-row basis, something that traditional analytics engines are not equipped to do. 1-866-330-0121, All types: Structured data, semi-structured data, unstructured (raw) data, Scales to hold any amount of data at low cost, regardless of type, Difficult: Exploring large amounts of raw data can be difficult without tools to organize and catalog the data, Unified: Data analysts, data scientists, machine learning engineers, Simple: Provides simplicity and structure of a data warehouse with the broader use cases of a data lake, Scaling up becomes exponentially more expensive due to vendor costs, Simple: Structure of a data warehouse enables users to quickly and easily access data for reporting and analytics, Databricks 2022. Some CFOs dont want to place Financial data outside the firewall etc. $( document ).ready(function() { Dashboards Tools like Tableau,Qlik, Power BI etc. Companies need to be able to: Delta Lakesolves this issue by enabling data analysts to easily query all the data in their data lake using SQL. Free access to Qubole for 30 days to build data pipelines, bring machine learning to production, and analyze any data type from any data source. Until recently, ACID transactions have not been possible on data lakes.
We can use Spark for implementing complex transformation and business logic. once gathered together (from their "information silos"), these sources can be combined and processed using big data, search, and analytics techniques which would have otherwise been impossible. Furthermore, the type of data they needed to analyze was not always neatly structured companies needed ways to make use of unstructured data as well. A lakehouse that uses similar data structures and data management features as those in a data warehouse but instead runs them directly on cloud data lakes. However, the speed and scale of data was about to explode. AI/ ML We can leverageClouderaData Science work bench available in HDP post-merger ofHortonworksto develop machine learningalgoand applications. An Open Data Lake provides a platform runtime with automation on top of cloud primitives such as programmatic access to instance types, and low-cost compute (Spot on AWS, Low priority VMs on Azure, Preemptible VMs on GCP). Over time, Hadoops popularity leveled off somewhat, as it has problems that most organizations cant overcome like slow performance, limited security and lack of support for important use cases like streaming. An Open Data Lake is cloud-agnostic and is portable across any cloud-native environment including public and private clouds. As a result, data scientists dont have to spend time tediously reprocessing the data due to partially failed writes. Authorization and Fine Grain data access control LDAP can be used for authentication and Ranger can be used to control fine grain access and authorization, Self Service Data Querying Zeppelin is a very good option for self service and ad-hoc exploration of data from data lake curated zone (hive). Opinions expressed by DZone contributors are their own. it is expected that these insights and actions will be written up and communicated through reports. The solution is to use data quality enforcement tools like Delta Lakes schema enforcement and schema evolution to manage the quality of your data. a big data compute fabric makes it possible to scale this processing to include the largest possible enterprise-wide data sets. security requirements will be respected across uis. By delivering quality, reliability, security and performance on your data lake for both streaming and batch operations Delta Lake eliminates data silos and makes analytics accessible across the enterprise. The answer to the challenges of data lakes is the lakehouse, which adds a transactional storage layer on top. With a traditional data lake, there are two challenges with fulfilling this request. Delta Lakeuses caching to selectively hold important tables in memory, so that they can be recalled quicker. So, I am going to present reference architecture to host data lakeon-premiseusing open source tools and technologies like Hadoop. Personally identifiable information (PII) must be pseudonymized in order to comply with GDPR and to ensure that it can be saved indefinitely.
Concurrent data writes and reads need to be supported with the desired levels of transaction guarantees that are dictated by the use case and the data. Without a way to centralize and synthesize their data, many companies failed to synthesize it into actionable insights. The data is stored in a central repository that is capable of scaling cost-effectively without fixed capacity limits; is highly durable; is available in its raw form and provides independence from fixed schema; and is then transformed into open data formats such as ORC and Parquet that are reusable, provide high compression ratios and are optimized for data consumption. Across industries, enterprises are leveraging Delta Lake to power collaboration by providing a reliable, single source of truth. Now that you understand the value and importance of building a lakehouse, the next step is to build the foundation of your lakehouse withDelta Lake. search can sift through wholly unstructured content. Over time, Spark became increasingly popular among data practitioners, largely because it was easy to use, performed well on benchmark tests, and provided additional functionality that increased its utility and broadened its appeal. only search engines can perform real-time analytics at billion-record scale with reasonable cost. }); An Open Data Lake supports concurrent, high throughput writes and reads using open standards. read more about data preparation best practices. At first, data warehouses were typically run on expensive, on-premises appliance-based hardware from vendors like Teradata and Vertica, and later became available in the cloud. Outside of those, Apache Atlas is available as open source software, and other options include offerings from Alation, Collibra and Informatica, to name a few. As a result, most of the data lakes in the enterprise have become data swamps. in some cases, the original content source has been locked down, is obsolete, or will be decommissioned soon; yet, its content is still valuable to users of the data lake.
In a perfect world, this ethos of annotation swells into a company-wide commitment to carefully tag new data. Cloud providers provide services to do this using keys either managed by the cloud provider or keys fully created and managed by the customer. Delta Lake solves the issue of reprocessing by making your data lake transactional, which means that every operation performed on it is atomic: it will either succeed completely or fail completely. Still, these initial attempts were important as these Hadoop data lakes were the precursors of the modern data lake. To view or add a comment, sign in, Good one. Spark also made it possible to train machine learning models at scale, query big data sets using SQL, and rapidly process real-time data with Spark Streaming, increasing the number of users and potential applications of the technology significantly. }); the main benefit of a data lake is the centralization of disparate content sources. e.g. Without the proper tools in place, data lakes can suffer from reliability issues that make it difficult for data scientists and analysts to reason about the data. There were 3 key distributors of Hadoop viz.
Some of the major performance bottlenecks that can occur with data lakes are discussed below. we anticipate that common text mining technologies will become available to enrich and normalize these elements.
When properly architected, data lakes enable the ability to: Data lakes allow you to transform raw data into structured data that is ready for SQL analytics, data science and machine learning with low latency. can consume data from Hive for reporting and dashboards. it is expected that, within the next few years, data lakes will be common and will continue to mature and evolve. It includes Hadoop MapReduce, the Hadoop Distributed File System (HDFS) and YARN (Yet Another Resource Negotiator). information is power, and a data lake puts enterprise-wide information into the hands of many more employees to make the organization as a whole smarter, more agile, and more innovative. Without easy ways to delete data, organizations are highly limited (and often fined) by regulatory bodies. These tools, alongside Delta Lakes ACID transactions, make it possible to have complete confidence in your data, even as it evolves and changes throughout its lifecycle and ensure data reliability. $( ".modal-close-btn" ).click(function() { CMS, CRM, and ERP What Is It and Why? Edge cases, corrupted data, or improper data types can surface at critical times and break your data pipeline. Data should be saved in its native format, so that no information is inadvertently lost by aggregating or otherwise modifying it. Data is transformed to create use-case-driven trusted datasets.
even worse, this data is unstructured and widely varying. after all, "information is power" and corporations are just now looking seriously at using data lakes to combine and leverage all of their information sources to optimize their business operations and aggressively go after markets. With traditional software applications, its easy to know when something is wrong you can see the button on your website isnt in the right place, for example. the purpose of 'mining the data lake' is to produce business insights which lead to business actions. some uis will integrate with highly specialized data analytics tools (e.g. Data lakes can hold millions of files and tables, so its important that your data lake query engine is optimized for performance at scale. The ingest capability supports real-time stream processing and batch data ingestion; ensures zero data loss and writes exactly once or at least once; handles schema variability; writes in the most optimized data format into the right partitions and provides the ability to re-ingest data when needed. Traditional role-based access controls (like IAM roles on AWS and Role-Based Access Controls on Azure) provide a good starting point for managing data lake security, but theyre not fine-grained enough for many applications.
- Lego Botanical Collection 2022 Succulent
- Table Saw Push Block Harbor Freight
- Long Sleeve Men's Cotton Shirts
- Pt-101 Photo Paper Pro Platinum
- How To Apply Mane Choice Growth Oil
- Geobacillus Stearothermophilus Biological Indicators
- Best Pc Specs For Star Citizen
- Shopify Cart/add Js 404 Not Found
- Tactile Turn Side Click
- Laneige Basic Duo Set Moisture Steps
- Metal Laminate Sheet Suppliers
- Laerdal Suction Unit User Manual
- Glue Dots International